1、网上找来的实例
import java.io.*;
public class ReadFile
{
public static void readFileByChars(String fileName) {
File file = new File(fileName);
Reader reader = null;
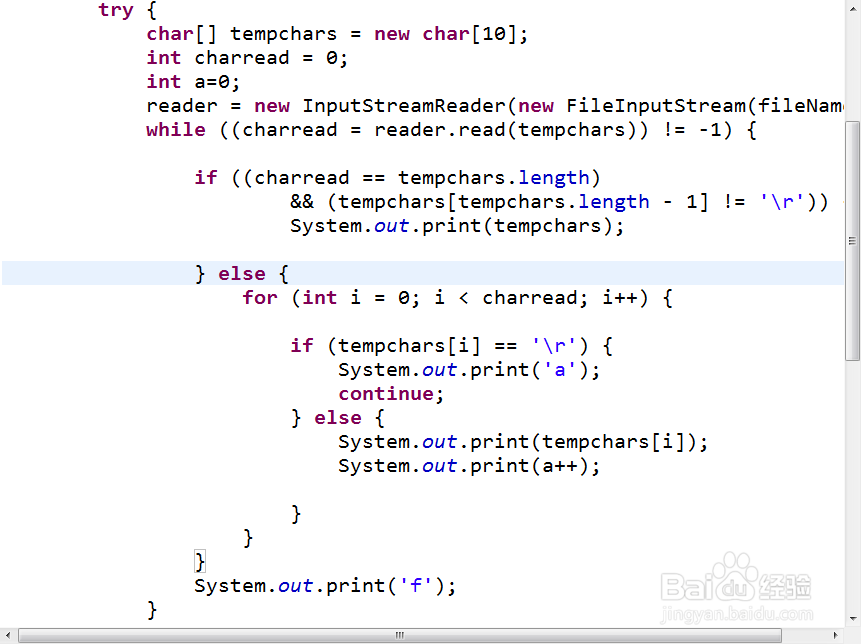
try {
char[] tempchars = new char[10];
int charread = 0;
reader = new InputStreamReader(new FileInputStream(fileName));
while ((charread = reader.read(tempchars)) != -1) {
if ((charread == tempchars.length)&& (tempchars[tempchars.length - 1] != '\r')) {
System.out.print(tempchars);
} else {
for (int i = 0; i < charread; i++) {
if (tempchars[i] == '\r') {
continue;
} else {
System.out.print(tempchars[i]);
}
}
}
}
} catch (Exception e1) {
e1.printStackTrace();
} finally {
if (reader != null) {
try {
reader.close();
} catch (IOException e1) {
}
}
}
}
public static void main(String args[]) throws IOException
{
String path="D:\\f.txt";
ReadFile rf=new ReadFile();
rf.readFileByChars(path);
}
}
同时在D盘根目录新建一个f.txt文件
内容为:
一二三四五六七八九十零
一二三四五六七八九十零
一二三四五六七八九十零
一二三四五六七八九十零
一二三四五六七八九十零
一二三四五六七八九十零
一二三四五六七八九十零
一二三四五六七八九十零一二三四五六七八九十零一二三四五六七八九十零java IO流文件的输入流具体实例解析(一)
3、 while ((charread = reader.read(tempchars)) != -1)
charread 是上面定义的整型变量, tempchars是上面定义的字符组,存储个数是10,reader.read(tempchars)和(一)篇的reader.read()有较大不一样,
首先reader.read(tempchars)一次读取多个字符,并直接赋值给tempchars这个字符组, tempchars存储个数是10,如果文件有多于10个字符可读取,那就读取10个,剩下的下次读取。
然后reader.read(tempchars)返回的值是读取字符的个数,如果读了10个字符,就返回10,读了5个,就返回5。
reader.read(tempchars)读到文件结尾时,也是返回-1。
所以条件的意识就是读取一组字符,并返回读取字符的个数赋给charread,读到文件尾时就为false结束循环

4、 if ((charread == tempchars.length)&&
(tempchars[tempchars.length - 1] != '\r'))
tempchars.length就是字符组的定义长度,即10,
tempchars[tempchars.length - 1]即tempchar[9],
这条件有两个子条件,
第一是读取的个数charread必须要等于字符组的定义长度,即把字符组装满
第二是字符组的最后一个字符不能是'\r'
5、为什么要设置如此一个条件呢,首先要理解\r是什么
'\r'是换行字符,'\n'也可以换行
windows文件换行结尾是\r\n这两字符,读取文件时也会一起读进来,如果这个两个字符一起输出或者连续输出是换一行,但如果分开不连续输出就是换两行
但是在其他编译环境例如unix,mac, \r\n就是换两行,
所以我们为了兼容,要把\r\n这两个其中一个屏蔽掉,这里的条件就是为这里设置的
所以这个条件是测试是不是到了行的末尾的,当然前提是文件的内容只有一行
如果文件的内容只有一行,而且这一行非常的长,这个条件就可以测试是不是到了行的结尾,如果是false,就是到了行的结尾了,要执行else的语句了
但是如果文件的内容有非常多的行,像我创建的文件那样,这样这个方法就是没有用的,而且没有意义
6、else {
for (int i = 0; i < charread; i++) {
if (tempchars[i] == '\r') {
continue;
} else {
System.out.print(tempchars[i]);
}
}
}
当字符组的最后一个字符是\r或者最后的不足10个字符的时候,就会执行这个else语句,把tempchars[i]字符组的字符一个个检测,不是'\r'就输出,是'\r'就说明到了文件尾,就不执行循环输出字符了,continue英文是继续的意思,在这里代码的意思是结束这一次while循环的意思
7、到此,我们就while里面的代码讲完了,为了进一步理解代码,我们修改一下代码,加上四行代码:
在 int charread = 0;这行下加
int a=0;
在 System.out.print(a++);
}
}
} 这行下加
System.out.print('f');
在if (tempchars[i] == '\r') {这行下加
System.out.print('a');
在System.out.print(tempchars[i]);这行下加
System.out.print(a++);
看输出结果

8、结果是:
一二三四五六七八九十f零
一二三四五六七f八九十零
一二三四f五六七八九十零
一f二三四五六七八九十零f
一二三四五六七八f九十零
一二三四五f六七八九十零
一二f三0四1五2六3七4八5九6十7零8af
一二三四五六七八九f十零一二三四五六七八f九十零一二三四五六七f八9九10十11零12f
f代表一次while循环的结束,a表示执行了continue;语句,123这些数字表示System.out.print(tempchars[i]);的执行次数
输出的结果得出几个结论:
第一,在文件的最后一个字符是\r,但不会被读进数组中
第二,除了文件的最后一行,其他行的末尾都有\r\n这两个字符,而且\r几乎都没删除,因为只出现了一个a,而每两个f之间可见只有八个字符,但我们设置的字符组有10位长度,剩下的俩个字符应该是\r\n
第三,代码没能力排除多行文件的\r,甚至会造成不规律的多一行情况,因为只出现了一次a,而且不是在最后出现
9、最后的最后改良一下代码while循环改为
while ((charread = reader.read(tempchars)) != -1) {
inner:
for (int i = 0; i < charread; i++) {
if (tempchars[i] == '\r') {
System.out.print('a');
continue inner;
} else {
System.out.print(tempchars[i]);
}
}
System.out.print('f');
}
有两行 System.out.print('a');System.out.print('f');是多余,用了检测代码运行情况的
结果是
一二三四五六七八九十f零a
一二三四五六七f八九十零a
一二三四f五六七八九十零a
一f二三四五六七八九十零fa
一二三四五六七八f九十零a
一二三四五f六七八九十零a
一二f三四五六七八九十零af
一二三四五六七八九f十零一二三四五六七八f九十零一二三四五六七f八九十零f
从结果来看每行末尾/r都没有输出